I thought I knew what scalability was. Just the same way most of us thought we knew what distributed systems were.
I realized I had to completely relearn these systems because of the cloud.
~Satya Nadella
There are a number of considerations that you as a developer, architect or engineering team have to make as your user base grows. Going from products with 10 to say 30 or a million and so forth has its considerations. This, of course, depends on the user base we are talking about.
Remember astute reader, a customer can be an organisation with a plethora of other members inside it, or just as well be a single user called Jack.
Explore with me
Imagine thousands, half a million and so forth people performing a search query against a server. If those queries land on your end, would it break? Would it be able to hold?

We should be able to handle more data, more concurrent connections and higher interaction rates.
A note on interaction rate:
How often a user changes the interface on a blog application vs a game.
Before we begin, it is important to note that setting up our product for scalability should be as easy and cheap to grow 10x as it should at 0.2x as is common with startups whose needs change rapidly over a short period of time.
Foremost, there are two types of scaling we need to observe.
a) Vertical scalability
b) Horizontal scalability
Both of the aforementioned have their pros and cons - each with a use case which would be deemed fit. Let's narrow this down.
Example :
For solo and relatively small ventures, you might opt for a VPS(virtual private server) which is essentially a physical machine holding multiple 'servers', yours included, each with its own OS and so forth. Once at a certain cap, you might see the need to increase resources and hence, the incremental hunt; more RAM, more storage, more CPU and so forth. almost everything gets more.
The example above, is one implementing vertical scaling, where, we upgrade the hardware and or the network throughput. In short, you do not need to modify your application architecture.
Vertical Scalability
Broken to bits, we resolve to a number of techniques.
- Adding more drives in RAID arrays and thus distributing our reads and writes during database interaction.
- Switching to solid-state drives from hard drives
- Increasing the RAM
- Adding more cores to the server to reduce the context switching.
- Upgrading network adapters, especially for systems reliant on media file processing.
There are a number of drawbacks, however. For instance, the change to a solid-state drive might not show a significant difference if working with MySQL which uses its own data structures for sequential disk operations or Cassandra. At a certain point, lock contention is bound to catch up and here, more CPU does little to any good. Vertical scaling also comes with a steep financial cost as you add more and more given the cash input doubles or triples as a unit of resource is added.
Example:
A RAM chip will double in cost as it grows in size. That is, x GB is $z , 2x GB is $2z and so forth. A reality check hits us once we get to a stage, say 128GB where the rules are not quite the same.
Horizontal Scalability
The alternative and preferred method - horizontal scaling. While it may come at a steep cost initially, it does get significantly cheaper as your enterprise grows to reach more users. Let's see how.
Caching
Use of content delivery networks (CDN)
To manage our assets, we save the hassle of having to perform the read and write operations on our own servers. Ever wondered why we have CDNs for most packages(Bootstrap, Material etc)?
Example:
We have our servers for, say UrbanDesk in South Africa. For access, an audacious Sergei (hint - thy knowest thyself) an enthusiastic early adopter from Germany, will hit the CDN(which are just data centres on their own). The CDN, acknowledging it lacks this data - images in our case, will hit our server for the resources it needs (CSS, images, javascript) and serve it to him while storing the same data and resources for further calls to the site. In this way, the next time, the call does not have to go a whole continent away.

Services like Cloudflare, Cloudinary or GoogleCloud CDN should ring a bell.
We have our static assets sorted out, but what about our data?
Edge Cache Servers
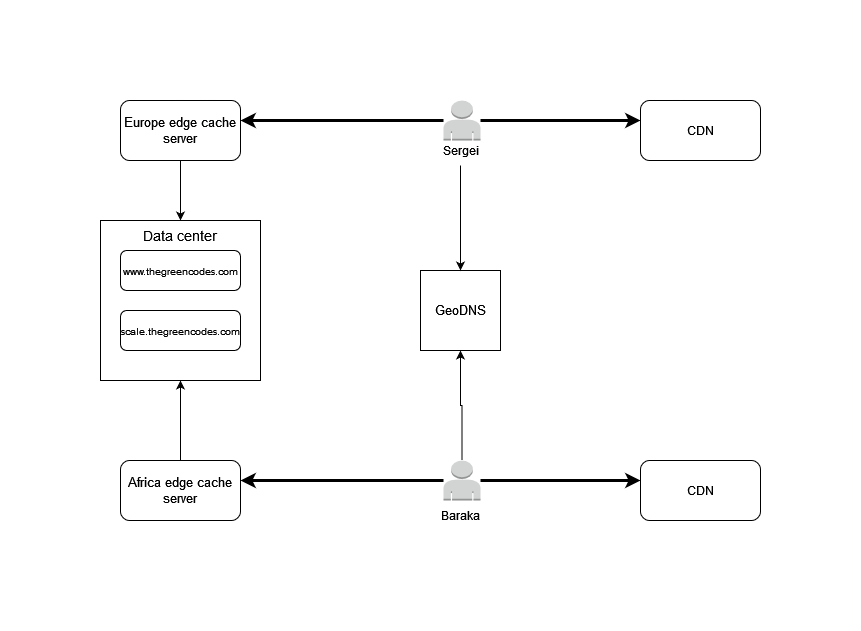
I've expounded on the data server to include functional partitioning, yet , another enhancement to our scaling needs. The concept behind it is that our project should be decomposed into individual actions those components need to perform - to group components of our application based on what they do.
For instance, we have sections that address this page you are currently reading (thegreencodes.com), then others that speak to different types of users, say, those interested in merch (merch.thegreencodes.com), or the admin (admin.thegreencodes.com). Each of these sections has been compartmentalized.
We might also move the database to its own server and update our configs to point to it, hence to each its own, that is, the server the application runs and the server the database runs are different but still communicating.
You will notice that I also added the GeoDNS. It works very similarly to an ordinary DNS, the only difference being that it is ' geo-tagged '.
The DNS
A Domain Name Server(DNS) is a way to identify your server's IP address on the web. In this way, if your server has an IP of say 127.0.0.1, it is displayed as example.com, to whoever else is looking at it.
Back to GeoDNS
Essentially, when you attempt to connect to thegreencodes.com, the server IP will be resolved to the data centre closest to you.
Elaborately, once your product has a certain cap of users , serving all across the globe, having a single server in a single location might degrade the experience these very users get.
Example
Google has multiple servers. While you might connect to its root domain from Australia and person B from Germany, these might not be served from the same server. The GeoDNS works to resolve the IP addresses of these servers/ data centers based on the location of the end user.
You will access the same data, only without knowledge of what IP the domain you are visiting is currently resolving to.
What makes horizontal scaling stand out is the basis on which it stands. At its core, horizontal scaling lets you deploy and maintain your project on several medium or small servers. A single server does not necessarily have to be extensive with vast amounts of resources - we split the load between different servers.
Of note, is that we need to consider whether our project is stateful or stateless. What this means is to identify whether the split needs data and whether that data needs to be synchronised.
Managing data in stateful horizontally scaled products
Behold, the CAP theorem and the ability to identify whether we need more reading or more writing of our database.
If we indeed have data that needs management, we might opt for three techniques.
a) Sharding by data b) Sharding by hash c) Data replication
On the one hand, we have sharding by data. In a case example similar to the one shown, we can have a database that holds data from those in Europe and another that holds data from those in America.
On the other hand, we can opt to use a consistent technique of hashing specific keys on our model and use those hashes to store data in different databases. For instance, hashing the profile_id and stating that data for users with the hash algorithm ABC will sit on this server and not the other.
The above are optimizations meant to prevent hitting the same database for all requests.
While not in-depth, I do intend to come back to this in future. So keep an eye up for this.
More than the type of scaling, we have to consider a number of techniques and practices to maintain.
As these platforms grow, the following have to be considered.
Testing
There is more to testing than unit tests. Larger systems eventually comprise of larger subsystems. How these systems work together (integration testing), whether the application is behaving according to the specification(functional testing), whether it can handle different loads (performance testing) and so forth.
Logging
The more the components, the more integration is needed and the more the system is prone to fail. The more servers we have, the higher the chances. We hope for the best, but prepare for the worst. Your team needs to know when a module went down, whether the data maintained its integrity, which modules are still up and so on.
Choose to go for the Crash-only approach; let the system always be ready for a crash and whenever it reboots, it should be able to continue without human interaction. An example of such a system is Netflix's Chaos Monkey which runs to kill random components of the system within working hours to test its reliability.
Conclusion
The practices above are intertwined. Functional partitioning would lead to the decomposition of the project, decomposition would lead to a 'maybe' use of microservices, this would bring a restructure of your team to smaller domain-driven teams, a change in how data is cached and managed and so forth. Build upon this. Go agile and iterate. This path is not linear, nor should it be treated as such.
Treat these principles as your northern star, but feel free to morph them based on the value they create for your business.
Understand
In the creation of sustainable software applications, we place the business logic at the centre. The inverse, you'll find, will get you great code, rather than solving the need to be addressed.
By placing technology first, we may get a great rails application, but it may not be a great pharmaceutical application ~ Robert C. Martin
Onto Architecture - the stuff we wish we'd gotten right at the start of our project.