Non-primitive non-linear data structures: Trees

When it comes to data storage, using linear structures, be it linked lists and arrays or even stacks and queues, we have accountability over time complexity as the size of our data increases. That is, the larger the data being stored, the more time it takes to extract this data or manipulate it.
'Ohh well great! You've shown me how to store data only to give me the cons afterward?! What on earth!'
Hold on for one moment, will you! That's why this piece is here. The non-primitive non-linear data structures.
As with family lines, from grandpa to great grandpa and yourself, so is the same applied to data structures.
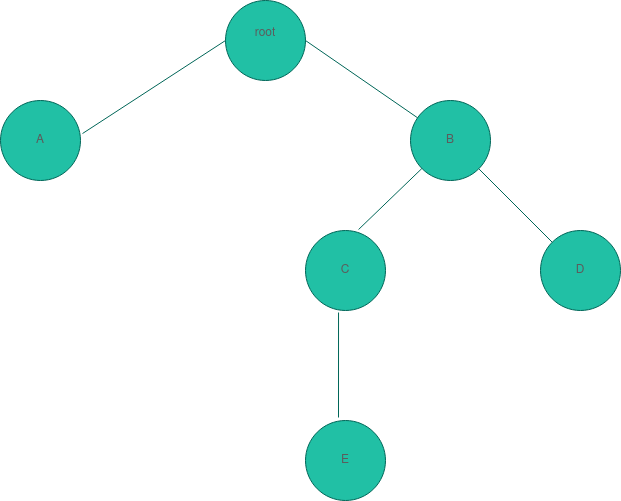
A little theory before we get into the why. We'll start off with the parent; the root.
It's from here that everything emanates. Just like a Linux directory structure. The / directory.
Our tree root has two 'children', A and B, defined by engineers as nodes. From here, we see B with its own pair of children, 'C' and 'D' of whom C proceeds to get a single child node 'E'. We might as well call C a parent at this point.
The little lines marking the links between parent and child would be named edges.
Following a specific path to the final child, for instance, following through to E would name this bottom descendant a leaf node or external node. It's the last child in this specific path with no children. The same applies to A and D.
Depth of nodes
The number of edges from the root to the node. In our case, E would have a depth of 3.
Height of a node
How far is the smallest child from it in this specific path? B, for instance, will have a height of 2. Given there are two edges before we get to the furthest descendant in its path. Depending on how many children it has, how far is the furthest child of a node? How many nodes does this child have?
Height of Tree
The height of a tree's root node.
Degree of Node
The number of children of a node. Above, C has a degree of one while B has that of two.
A practical train of thought. We have data to be queried from an API REST endpoint. Our system has users, profiles, and articles. Thinking logically, a user profile is a child node of the user's endpoint. We will have to get a user to log in, get the token, and query the profile based on the token. Something like this:
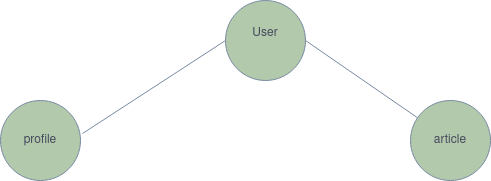
So in your thought process, seeing as it is, software development is more of thinking than writing code, it would make sense to create a user model before a profile. Our User model is the parent, the root.
Compare this to having a linear data structure.
We could go on to break trees into more individual types:
a) General Tree
b) Binary Tree
c) Binary Search Tree
d) AVL Tree
Binary Tree
A tree, as displayed above, in which case parents have at max, two children. Due to this, the children are referred to as the left and right child. Think of how we might have this in decision trees, where we perform an action based on a condition. To elaborate further, we have the below groups.
Full Binary tree
Every node of the tree has two or zero children.
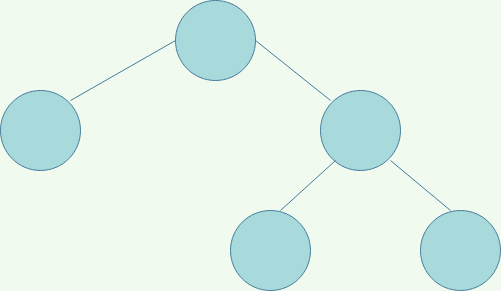
Perfect Binary Tree
The tree internal nodes have two children. All leaves also have the same depth. A perfect uniform.
Balanced Tree
If the height of the left and right subtree at any node differs at most by 1, then the tree is called a balanced tree. So in the case of the perfect binary, if either of the last child nodes had one more child, one and only one, it would become a balanced tree. It's a strange way of calling something balanced, I know!
General Tree
Consider a binary tree. Any type of binary tree, but without limitations to what number of children a node can have. Do you want 4? Do you want 17? Go ahead and fill your database or whatever it is your structuring.
Binary Search Tree
A different way of looking at Binary search trees if you may. Here, the left nodes are always smaller than their parents in terms of the value they possess. The right nodes, however, are a little cocky, always having more value than their parents or being equal.
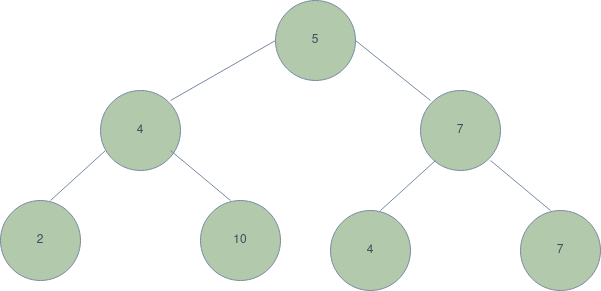
'Well, that's not right. I've never seen this man in my life!'
Used maps/dictionaries before? Yeap. binary search trees you deserter!
Searching for a specific item in an array of 100 or 200 might not be a problem. Increase this to 10 000 or 1 000 000 items, however, no one wants to be the user.
AVL Tree
Named after Adelson, Velsky, and Landis, this is a self-balancing binary tree in which each node has extra information - the balance factor- whose value is either -1, 0, or 1.
You remember [heights](####Height of a node), right? Well, the balance factor comes in as below:
BalanceFactor = height_of_left_subtree - height_of_right_subtree
Whenever a tree is out of balance, AVL trees work around this by rotating nodes. Whether moving the right node to the left or the right, or left-right rotation or perhaps right-left rotation.
What this means is that at one point, the right node which seemed heavy/ larger to the left will become the parent and hence the parent becomes the left child while the left child becomes the new right child and so on. think of it in terms of the hour clock. It will rotate itself in either direction until the tree is balanced. More detail on this can be elaborated on in a later conversation. Keep an eye up!
Conclusion
We've taken a bucket load of information. Trees and searching, children, and siblings. What is all this knowledge without implementation? Fire up that laptop one last time this year and think of how you could have consumed that endpoint differently. Take a sabbatical, if you may, and have the rest you need, then come back and break the time complexity barrier. Write more efficient code, more productive code, and let's make the user experience smoother.
Here,