Recommendation systems on the web
The internet knows you better than you know yourself

Introduction
I have a confession to make; I am a huge fan of sci-fi.
Whether it is another episode of The Minority Report, Upload or Travelers, I am all for it. Perhaps the underlying cause is my fascination with how these societies use technology in their everyday lives. Moreso, perhaps it is in the chance to witness something that is on the brink of discovery in our modern-day information era.
One of the common theme that appears across these films is the ability of machines to predict what we want.
An observer need only take one look at how, say the show, The Minority Report, uses its predictive algorithm Hawk-Eye, to predict the occurrence of crime and compare it to Essex University’s KeyCrime, to see a closeness between fiction and reality.
What if we could predict what would happen before it does? What if a machine could tell what you would buy before you actually get to it?
What is a Recommendation System?
A recommendation system is an information filtering technique that predicts what a user might prefer based on their historical interactions or preferences.
As an example, and coming back from our high on KeyCrime, if a user frequently watches romantic comedies on a streaming service, a recommendation system may suggest similar movies or TV shows. These systems are based on machine learning algorithms that analyze user behaviour to generate other details that they might be interested in.
They have become commonplace in industries such as e-commerce, social media platforms, security and healthcare. Let’s talk about this and the different aspects that come to play around recommendation engines.
Types of Recommendation Systems
For brevity, there are different types of recommendation systems, including content-based, collaborative-based, hybrid, and demographic-based recommendations.
Content-based Recommendation
Say, for instance, you are called Ian, and you have a thing for apple products. You log into Instagram and double-tap on two or three images around apple products or advertisements. What happens in the background?
Content-based recommendation systems make recommendations based on the similarity of items and are attached to the particular user. the more interaction you have with a system, the more accurate the data gets. In essence, a content-based recommendation engine needs a base item(s) around which a user’s actions(reviews, likes etc…) can be pegged.
“We see you liked an image that has wheat. Here are other wheat-based products you might relish.”
Collaborative-based Recommendation
What if we have a whole community of foodies? Could they ping each other based on what they enjoyed preparing?

Collaborative-based recommendation systems generate recommendations based on the behaviour of similar users. If two users have similar preferences, the system will recommend items that one user has liked to the other.
The Netflix Prize was one such event where builders across the board were invited to a collaborative filtering algorithm challenge to improve upon its own algorithm, Cinematch. A grand prize of $1000 000 for any team that came through with the solution.
Broadly speaking, collaborative-based recommendation systems are grouped into memory and model-based. For purposes of this guide, we shall focus on memory-based collaborative filtering within which we can further break into Item and user-based collaborative filtering.
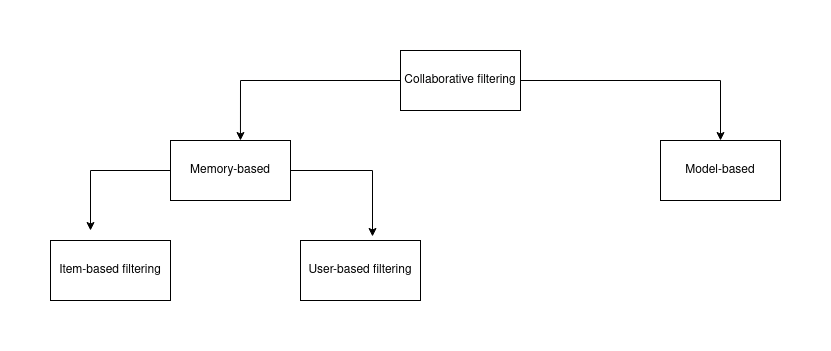
User-based collaborative filtering
At its core, user-based collaborative filtering is based on similar consumption patterns.
Example: Let’s say Rita finally set up her restaurant. We pay a visit, and you give it a 5-star rating. Now, your friend, Peter, does the same. Already, we have two users with a similar rating on the same location. It is very likely that because Rita and Peter have a 5-star rating on a specific item, they will have other items in common. Thus, we look for people with a rating of between 5 and 3.5 for the restaurant and suggest other restaurants they like to you.
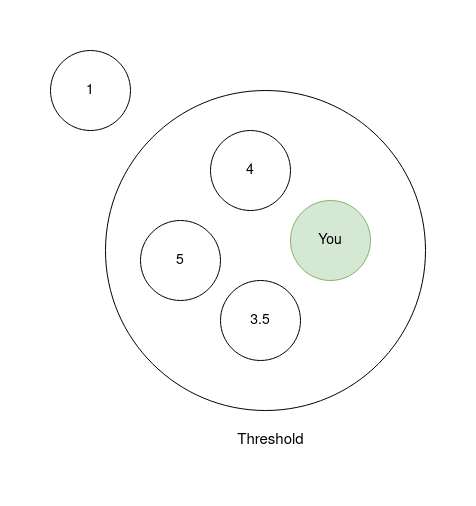
This ‘envelope’ we just created in our example is called a threshold. So, a user with a rating of 1 on the said restaurant will not be a source of suggestions for our next restaurant hopping experience.
Item-based collaborative filtering
Example: Most users that buy bread also buy butter. therefore, these items must be similar. Or if user X likes films with ‘Iron man’ then they will like those with ‘Spiderman’. You get the gist.
Introduced by Amazon in 1998, item-based filtering bases recommendations on similarities between items. This decision will affect our ‘pre-sales’ option during checkout. The suggestion is to get this customer to buy one more item, that is, spend more. This is the reason why everything in retail stores is where it is. Nothing by chance, nothing random.
Are there challenges to collaborative filtering? Well, certainly. Depending on which of the aforementioned you use you might encounter the following:
- The early rater problem
So, you successfully have a user log in to your platform with 20 000 books. They rate 1 / 20 000. We literally have nothing to recommend.
- Sparsity
You have a number of users all of whom have rated a significant count of products. However, these items are too far spread apart. Say, for instance, back to books, only two have rated the same books. All the others have rated items with no duplication.
- A gray sheep
You know yourself. You like to remain unpredictable, you open browsers in incognito all the time, like random things every time and leave the platforms you visit. Just like Elle(laughs like Mojo Jojo).
- The shilling attack
This happens when a single user or group of people create multiple accounts on the same platform and rate , say a product in a certain way in order to sway other users’ interest to the items they are rating highly. It can also happen to sway users away from a product by giving it bad ratings.
Hybrid Recommendation
Certainly, we must have come up with a workaround content and collaborative-based recommendation engines. In comes Hybrid recommendations.
Hybrid engines combine both content-based and collaborative-based approaches to generate recommendations.
Demographic-based Recommendation
Do you remember the piece, Up and Away with Scalability - specifically on caching and content delivery servers?
Demographic-based recommendation systems make recommendations based on demographic information such as age, gender, or location.
For one, we could have a location that is known for a type of music. Thus, instead of having our data centre closest to them caching everything and all other genres, why not cache what people actually listen to?
Pro tip: Bongo, a music genre, is popular in the coastal regions of Kenya and Tanzania. My music service would therefore hold a cache for this genre on servers closest to these regions as opposed to , say Alaska.
Demographic-based recommendation systems are often used for marketing purposes and can be particularly useful for identifying and targeting specific groups of users.
Applications of Recommendation Systems
A favourite example I like to reference when it comes to recommendation engines is one highlighted in the book, The Power of Habit, by Charles Duhigg, of the American retail store, Target.
Target’s data analytics team got so good at building these systems, it got into the public limelight when it suggested diapers in one of its marketing campaigns to a father who was sure his daughter was not. It recommended products users might want to purchase based on their patterns and on the data of other people they collected using their gift cards.
Other examples you might find interesting include how, for instance, LinkedIn uses the “You may also know” or “You may also like” for companies or profiles to follow.
Thought: Did you know , Netflix has gone through phases in its Personalization using recommendation systems?
What does this mean for the products in the build process?
For a preview, you can take a sneak peek into marvinkweyu/marastore - an e-commerce platform for travellers and backpackers. It includes within it, an item-based collaborative filtering engine. We dare answer;
Does user A need product Y given user B bought X and Y?
Back to you, the reader: How would you rank the aforementioned results?
Another example of a similar implementation is the library project, "Urbanlibrary" - the Afrocentric literature bookshelf. Within it, I implemented a mix-and-match if you may of recommendation algorithms. Is it based on history? Is it based on rating? You’ll never know unless you find out.
Conclusion
Recommendation systems have evolved to suit different needs and algorithms have been built on top of each other to meet this demand. You can combine, break away from, build your own or adopt an existing solution. Either way, it offers a path to understanding your customers and business. Take advantage. Personalize this experience.
Indulge: Perhaps all you need to be a mind reader is your browser history.